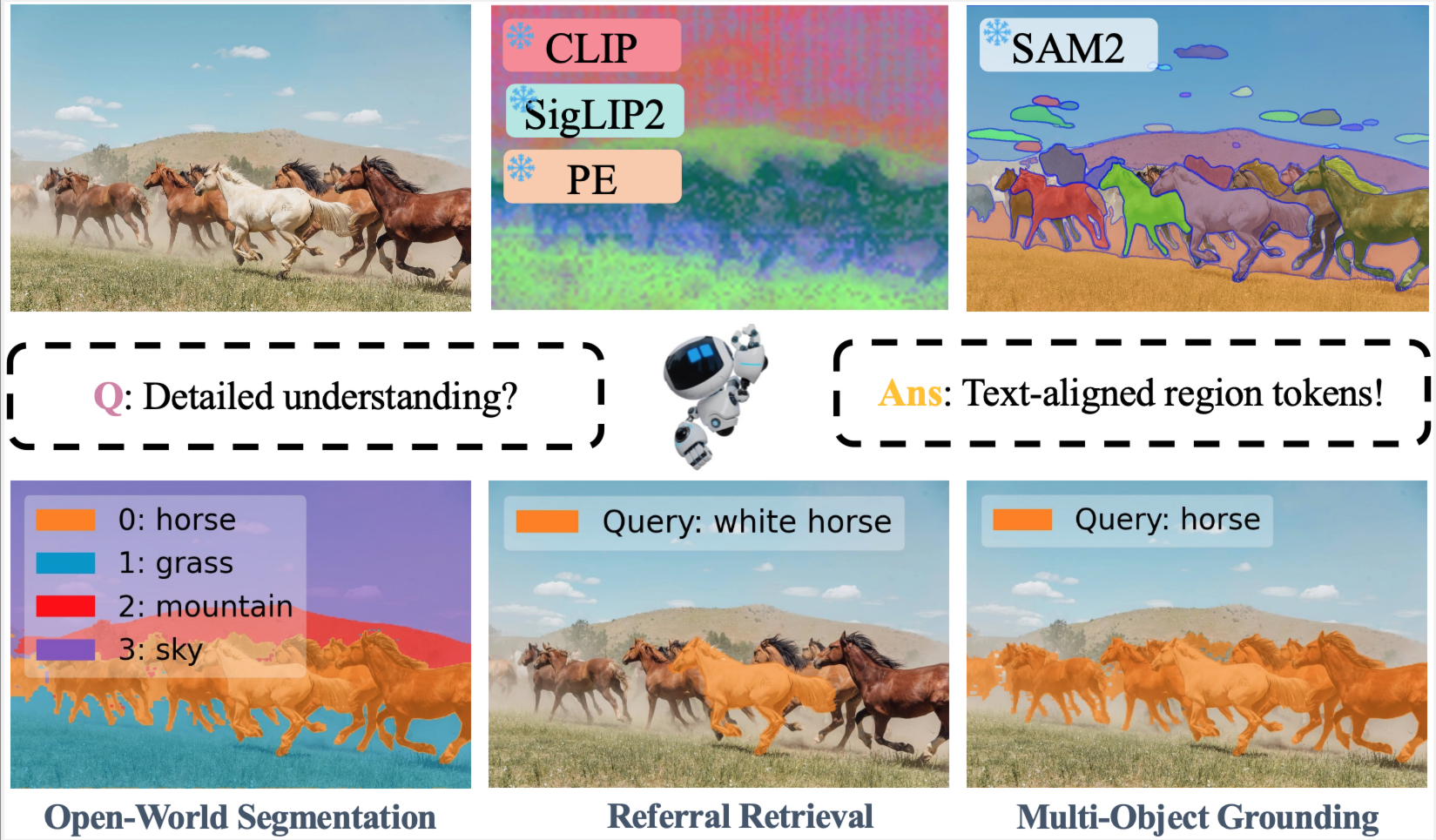
TextRegion: Text-Aligned Region Tokens from Frozen Image-Text Models
Yao Xiao, Qiqian Fu, Heyi Tao, Yuqun Wu, Zhen Zhu, Derek Hoiem
Under Review.